Scalability ဆိုတာကတော့ လက်ရှိ ရှိနေသည့် system ကို scale လုပ်လို့ရအောင် လုပ်ထား တယ်လို့ ဆိုနိုင်ပါတယ်။ Scale လုပ်တယ်ဆိုတာက လက်ရှိ လူ ၁၀ ယောက်လောက် သုံးနေချိန်မှာ server အသေးပဲ လိုပေမယ့် လူ အယောက် ၁ သန်း သုံးသည့် အချိန်မှာတော့ လက်ရှိ server နဲ့မရတော့ပါဘူး။
Horizontal Scale , Vertical Scale
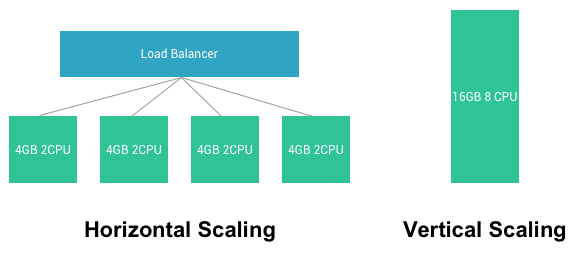
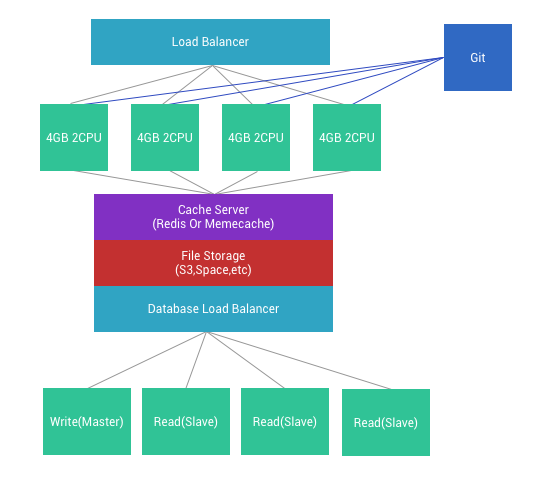
Scaling လုပ်သည့် အပိုင်းမှာ ၂ မျိုး ရှိပါတယ်။ Horizontal လုပ်မလား Vertical လုပ်မလား ဆိုပြီး ရှိပါတယ်။ Vertical ကတော့ လက်ရှိ ရှိနေသည့် server spec ကို တိုးလိုက်တာပါ။ အလွယ်ဆုံး နဲ့ အမြန်ဆုံး ပါပဲ။ သို့ပေမယ့် အမြင့်ဆုံး အမြန်ဆုံး server နဲ့ တောင် မလောက် ရင် ဘယ်လိုလုပ်မလဲ ? နောက်ပိုင်းမှာတော့ Vertical ထက် Horizontal scale ကို ပိုပြီး အသုံးပြုကြပါတယ်။ Horizontal scal ဆိုတာကတော့ server အသေးတွေ အများကြီးကို Load balancer တစ်ခု ခံပြီး အသုံးပြုကြပါတယ်။ Horizontal scaling ဟာ vertical scaling ထက် ငွေကုန် သက်သာပါတယ်။ နောက်ပြီးတော့ လိုသလောက် အတိုးအလျော့ လွယ်လင့် တကူ လုပ်နိုင်တယ်။
Concurrency
Horizontal scaling ဟာ vertical scale ထက် concurrency ပိုပြီး ခံနိုင်ရည် ရှိပါတယ်။ server တစ်ခု တည်းမှာ load မရှိပဲ server တွေခွဲ ပြီးတော့ လုပ်ဆောင်ပါတယ်။
Thread Pool,Connection, Workers
Vertical scaling လုပ်ရင် Web server မှာ max connection တွေ တိုးဖို့ လိုပါတယ်။ တစ်ခါ scale လုပ်တိုင်း max connection , thread pool, workers စတာတွေကို ပြန်ပြီး ချိန် ညှိပေးဖို့ လိုတယ်။ အဲလို မချိန်ညှိထားရင် vertical scale က သိပ်ပြီး အလုပ်ဖြစ်မှာ မဟုတ်ပါဘူး။ Horizontal scale ကတော့ လက်ရှိ server ကိုပဲ clone လုပ်ပြီး သုံးတာ ဖြစ်သည့် အတွက်ကြောင့် thread, connection စတာတွေ ပြန်ချိန်ဖို့ မလိုတော့ပါဘူး။
Cache Server
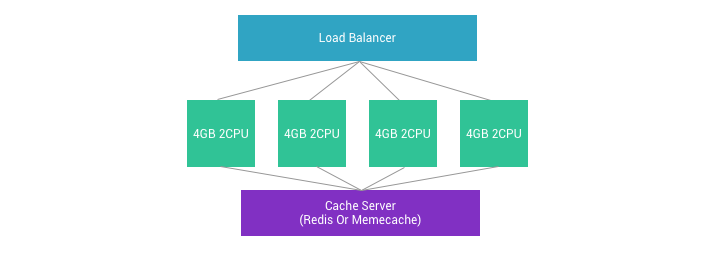
Scalability ဖြစ်အောင် မဖြစ်မနေ cache server လိုအပ်ပါတယ်။ Cache ကို memcache , redis စတာတွေကို အသုံးပြုနိုင်တယ်။ အဓိက memory base ဖြစ်ဖို့ လိုတယ်။ File Cache ထက်စာရင် memory base cache တွေက ပိုပြီး မြန်တယ်။ ဒါကြောင့် code ရေးသည့် အခါမှာလည်း cache ကို မဖြစ်မနေ ထည့်သွင်းရေးရတယ်။
Caching ပိုင်းက လွယ်လွယ်လေးလို့ ဆိုပေမယ့် ဘယ်အချိန်မှာ cache ဖျက်မယ်။ cache ထားမယ်။ ဘာတွေကတော့ cache ရှိဖို့ လိုတယ်။ ဘာတွေကတော့ cache ထားလို့ မဖြစ်ဘူးဆိုတာကို နားလည်ဖို့ လိုတယ်။
Cache Server ကို သီးသန့် ခွဲထုတ်ထားမှသာ server အကုန်လုံးက cache တစ်ခု တည်း အနေနဲ့ အလုပ်လုပ်နိုင်ပါလိမ့်မယ်။ Local file cache ဆိုရင် server တစ်ခု ခြင်းဆီက cache ကို အလုပ်လုပ်နေရပါမယ်။
Storage
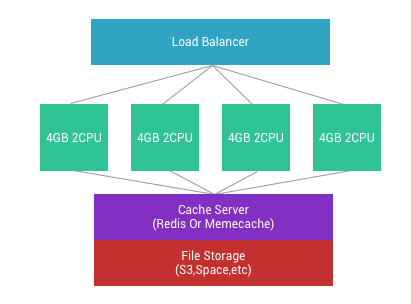
Multi-server ဖြစ်သွားသည့် အခါမှာ static file တွေကို တစ်နေရတည်းမှာ အသုံးပြု နိုင်ရင် ပိုကောင်းပါတယ်။ Amazon S3, Digital Ocean Space လိုမျိုး file storage တွေမှာ သိမ်းပြီးတော့ CDN နဲ့ ခေါ်သုံးတာ ပိုအဆင်ပြေပါလိမ့်မယ်။ Multi server ဖြစ်သည့် အတွက်ကြောင့် တစ်နေရာမှာ javascript , css ကို ပြင်လိုက်ရင် အကုန်လုံးမှာ လိုက်ပြောင်းဖို့ အတွက် မလွယ်လှပါဘူး။ Static အတွက် Storage တစ်ခုခု ကိုသုံးထားပြီးတော့ အဲဒီ file ကို access လုပ်တာ အဆင်ပြေဆုံးပါပဲ။ အဲဒီလို မဟုတ်ရင်တော့ Server ၅ လုံးရှိရင် ၅ လုံး စလုံး ပြန်ပြီး update လုပ်နေရပါလိမ့်မယ်။
အကယ်၍ user profile တွေပါလာခဲ့ရင် profile picture ကို upload လိုက်တာနဲ့ အခြား server တွေကနေလည်း access ရနေဖို့လိုတယ်။ ပုံမှန် local ထဲမှာ သိမ်းမယ့် အစား S3 လိုမျိုး file storage မှာ သိမ်းသည့် အခါမှာ အခြား server တွေက လွယ်လင့် တကူ ပြန်ပြီး ရယူနိုင်ပါတယ်။
Backend ကနေ ပုံတစ်ပုံတင်လိုက်တယ်ဆိုရင် သမာရိုးကျ ကတော့ file အနေနဲ့ လက်ရှိ server မှာ သိမ်းသွားတယ်။ /var/www/domains/blabla.com/storage/pic1.jpg ဆိုပြီးတော့ပေါ့။ အဲဒါဆိုရင် အဲဒီ server ကနေပဲ access လုပ်လို့ရမယ်။ အခြား server မှာ file မရှိသည့်အတွက် ကြောင့် အဆင်မပြေဘူး။ ဒါကြောင့် မဖြစ်မနေ s3 လိုမျိုး storage တစ်ခုခုကို အသုံးပြုရပါတယ်။
Git
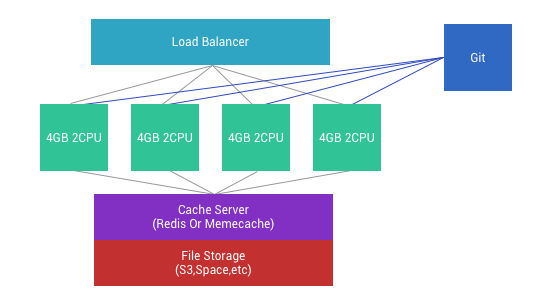
မဖြစ်မနေ Git သို့မဟုတ် version control system တစ်ခုခု ကို သုံးဖို့လိုအပ်တယ်။ File တစ်ခုခု ပြင်တာနှင့် production မှာ တစ်ခုခြင်းဆီ လိုက်ပြင်နေမယ့် အစား pull ဆွဲချတာ ပိုအဆင်ပြေတယ်။ Server 5 လုံးမှာ file 10 ခု လောက်ကို တစ်ခုခြင်းစီ လိုက်ပြင်နေ ဖို့ မလွယ်ဘူး။ ဒါကြောင့် Git ကို အသုံးပြုပြီးတော့ server မှာလည်း file တွေကို git ကနေ ပဲအသုံးပြုတာ ပိုအဆင်ပြေပါလိမ့်မယ်။
ပုံမှန်အားဖြင့် developer တွေဟာ production server ပေါ်မှာ အရေးပေါ် fix လုပ်တာတွေ ရှိတတ်တယ်။ Mutli Server ဖြစ်သွားသည့် အခါမှာ အဲလို လုပ်လို့ မရတော့ဘူး။ Server တစ်ခု ခြင်းစီကို fix code တွေ လိုက်ဖြည့်တာ အချိန်ကြာသလို ကျန်ခဲ့တာတွေလည်း ရှိနိုင်တယ်။ ဒါကြောင့် မဖြစ်မနေ git ကို အသုံးပြုစေချင်တယ်။
Database
Code က ရေးထားတာ ကောင်းပေမယ့် database ပိုင်းကို သေချာမလုပ်ထားရင်လည်း အဆင်မပြေပါဘူး။ အခု ဆောင်းပါးက Scalability ဖြစ်နေတာကြောင့် high performance အကြောင်းကို နောက်မှ ပြောပါမယ်။
MySQL ကို scale လုပ်ဖို့ လွယ်တော့ မလွယ်ပါဘူး။ ပုံမှန် အားဖြင့် Read/Write Database ခွဲပြီးတော့ master slave replication လုပ်ကြတယ်။ Read ပဲရှိပြီး write မရှိသည့် database နဲ့ write ပဲ အဓိက လုပ်သည့် database ကို ခွဲကြပါတယ်။
သို့ပေမယ့် master slave replication က နေရာတိုင်း အတွက် အဆင်မပြေပါဘူး။ Database ပိုင်းမှာလည်း scale လုပ်သည့် အခါမှာ performance အတွက်လား data safety အတွက် လား ဆိုပြီး စဉ်းစားနိုင်တယ်။ Data safety အတွက် ဆိုရင် Multi Master replication ကို အသုံးပြုနိုင်တယ်။ သို့ပေမယ့် performance က data များလာလေလေ ကျလာလေလေ ဖြစ်နိုင်တယ်။
အများအားဖြင့် Master Slave ကို အသုံးပြုကြတယ်။ Master ကို Delete/Update/Insert အတွက် သုံးပြီး Read ကိုတော့ Slave Replica တွေကနေ ဖတ်ကြတာ များတယ်။ Master နဲ့ ပုံမှန် sync လုပ်နေဖို့ လိုပါတယ်။ အဲလိုမျိုး ကိစ္စတွေ အတွက် HAProxy နဲ့ တွဲပြီး အသုံးပြုကြတာ များပါတယ်။ Port တစ်ခုကို read query အတွက် အသုံးပြုပြီးတော့ write အတွက်ကို အခြား port တစ်ခု နဲ့ အသုံးပြုနိုင်တယ်။ Code အနေနဲ့ database တစ်ခု ထက်ပိုပြီး handling လုပ်နိုင်အောင် ဖန်တီးထားဖို့ လိုတယ်။
အခုနောက်ပိုင်း Maria DB မှာ MaxScale ဆိုတာ ထွက်လာပါတယ်။ Read-write splitting အလိုလို ဆောင်ရွက်ပေးနိုင်တယ်။ Query Caching တွေပါတယ်လို့ ဆိုပါတယ်။ Sharding ပါ support လုပ်တယ်လို့ ဆိုပါတယ်။
MySQL မှာတော့ MySQL Router ဆိုပြီး ထုတ်ထားပါတယ်။ MySQL Community Edition မှာ support လုပ်တယ်လို့ ဆိုပါတယ်။
အခြား database တွေ လည်း scaling လုပ်ဖို့ သူ့နည်းသူ့ဟန် နဲ့ ရှိကြပါတယ်။ အများအားဖြင့် Master/Slave (Read/Write) replication သို့မဟုတ် Sharding ကို အသုံးပြုကြပါတယ်။
Scalable ?
လက်ရှိ ရေးထားသည့် code တွေက scalable ဖြစ်ရဲ့ လား ဆိုတာ ပြန်စစ်ဆေးကြည့်သင့်ပါတယ်။
လက်ရှိ project မှာ
1. Git အသုံးပြုပြီး deploy လုပ်နေသလား ?
2. Cache Server သုံးမယ် ဆိုရင်ကော အဆင်ပြေလား ? လွယ်လင့် တကူ ထည့်သုံးနိုင်လား ?
3. File Upload တွေကို သီးသန့် class ခွဲထားလား။ static file တွေကို config နဲ့ url လုပ်ထားလား ? အခု အချိန်မှာ s3 ပြောင်းသုံးမယ်ဆိုရင် ချက်ခြင်း ပြောင်းပေးနိုင်လား ?
4. Database ကို တစ်ခုထက် ပိုပြီး ရေးနိုင်ဖတ်နိုင်လား ? DB connection က တစ်ခုပဲ အသုံးပြုလို့ ရနေတာလား ?
Scalable လုပ်နိုင်ပေမယ့် code quality နဲ့ database design/setup က high performance မဟုတ်ရင်တော့ သိပ်ပြီး မထူးလှပါဘူး။ High Performance ဖြစ်အောင် Coding Skills အပြင် database knowledge ပိုင်းလည်း ကောင်းမွန်စွာ နားလည်ဖို့လိုအပ် ပါတယ်။ Database အပိုင်းနဲ့ ပတ်သက်ပြီး နောက်မှ post တစ်ခု ထပ်ရေးပါအုံးမယ်။